17 Exercise 1: Word frequency analysis
17.1 Introduction
In this tutorial, you will learn how to summarise, aggregate, and analyze text in R:
- How to tokenize and filter text
- How to clean and preprocess text
- How to visualize results with ggplot
- How to perform automated gender assignment from name data (and think about possible biases these methods may enclose)
17.2 Setup
To practice these skills, we will use a dataset that I have already collected from the Edinburgh Fringe Festival website.
You can try this out yourself too: to obtain these data, you must first obtain an API key. Instructions on how to do this are available at the Edinburgh Fringe API page:
17.3 Load data and packages
Before proceeding, we’ll load the remaining packages we will need for this tutorial.
library(tidyverse) # loads dplyr, ggplot2, and others
library(tidytext) # includes set of functions useful for manipulating text
library(ggthemes) # includes a set of themes to make your visualizations look nice!
library(readr) # more informative and easy way to import data
library(babynames) #for gender predictionsFor this tutorial, we will be using data that I have pre-cleaned and provided in .csv format. The data come from the Edinburgh Book Festival API, and provide data for every event that has taken place at the Edinburgh Book Festival, which runs every year in the month of August, for nine years: 2012-2020. There are many questions we might ask of these data. In this tutorial, we will investigate the contents of each event, and the speakers at each event, to determine if there are any trends in gender representation over time.
The first task, then, is to read in these data. We can do this with the read_csv() function.
The read_csv() function takes the .csv file and loads it into the working environment as a data frame object called “edbfdata.” We can call this object anything though. Try changing the name of the object before the <- arrow. Note that R does not allow names with spaces in, however. It is also not a good idea to name the object something beginning with numbers, as this means you have to call the object within ` marks.
edbfdata <- read_csv("data/wordfreq/edbookfestall.csv")## New names:
## Rows: 5938 Columns: 12
## ── Column specification
## ───────────────────────────────────────── Delimiter: "," chr
## (8): festival_id, title, sub_title, artist, description, ... dbl
## (4): ...1, year, latitude, longitude
## ℹ Use `spec()` to retrieve the full column specification for
## this data. ℹ Specify the column types or set `show_col_types =
## FALSE` to quiet this message.
## • `` -> `...1`If you’re working on this document from your own computer (“locally”) you can download the Edinburgh Fringe data in the following way:
edbfdata <- read_csv("https://raw.githubusercontent.com/cjbarrie/RDL-Ed/main/02-text-as-data/data/edbookfestall.csv")17.4 Inspect and filter data
Our next job is to cut down this dataset to size, including only those columns that we need. But first we can inspect it to see what the existing column names are, and how each variable is coded. To do this we can first call:
colnames(edbfdata)## [1] "...1" "festival_id" "title" "sub_title"
## [5] "artist" "year" "description" "genre"
## [9] "latitude" "longitude" "age_category" "ID"And then:
glimpse(edbfdata)## Rows: 5,938
## Columns: 12
## $ ...1 <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13,…
## $ festival_id <chr> "book", "book", "book", "book", "book", "b…
## $ title <chr> "Denise Mina", "Alex T Smith", "Challengin…
## $ sub_title <chr> "HARD MEN AND CARDBOARD GANGSTERS", NA, NA…
## $ artist <chr> "Denise Mina", "Alex T Smith", "Peter Cock…
## $ year <dbl> 2012, 2012, 2012, 2012, 2012, 2012, 2012, …
## $ description <chr> "<p>\n\tAs the grande dame of Scottish cri…
## $ genre <chr> "Literature", "Children", "Children", "Lit…
## $ latitude <dbl> 55.9519, 55.9519, 55.9519, 55.9519, 55.951…
## $ longitude <dbl> -3.206913, -3.206913, -3.206913, -3.206913…
## $ age_category <chr> NA, "AGE 4 - 7", "AGE 11 - 14", NA, "AGE 1…
## $ ID <chr> "Denise Mina2012", "Alex T Smith2012", "Pe…We can see that the description of each event is included in a column named “description” and the year of that event as “year.” So for now we’ll just keep these two. Remember: we’re interested in this tutorial firstly in the representation of gender and feminism in forms of cultural production given a platform at the Edinburgh International Book Festival. Given this, we are first and foremost interested in the reported content of each artist’s event.
We use pipe %>% functions in the tidyverse package to quickly and efficiently select the columns we want from the edbfdata data.frame object. We pass this data to a new data.frame object, which we call “evdes.”
# get simplified dataset with only event contents and year
evdes <- edbfdata %>%
select(description, year)
head(evdes)## # A tibble: 6 × 2
## description year
## <chr> <dbl>
## 1 "<p>\n\tAs the grande dame of Scottish crime fiction, De… 2012
## 2 "<p>\n\tWhen Alex T Smith was a little boy he wanted to … 2012
## 3 "<p>\n\tPeter Cocks is known for his fantasy series Tris… 2012
## 4 "<p>\n\tTwo books by influential journalists are among t… 2012
## 5 "<p>\n\tChris d’Lacey tells you all about The Fire… 2012
## 6 "<p>\n\tIt’s time for the honourable, feisty and c… 2012And let’s take a quick look at how many events there were over time at the festival. To do this, we first calculate the number of individual events (row observations) by year (column variable).
And then we can plot this using ggplot!
ggplot(evtsperyr) +
geom_line(aes(year, sum_events)) +
theme_tufte(base_family = "Helvetica") +
scale_y_continuous(expand = c(0, 0), limits = c(0, NA))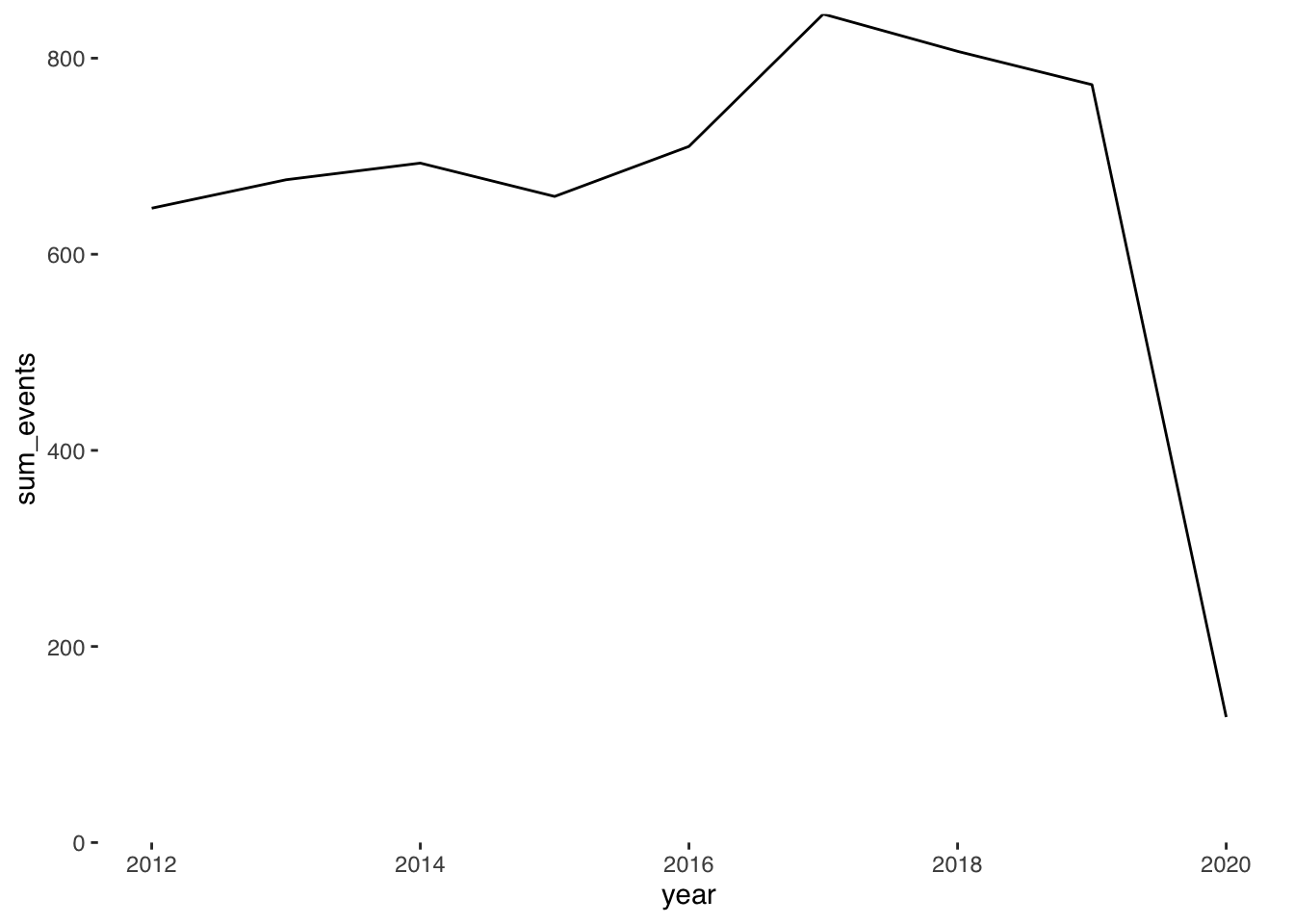
Perhaps unsurprisingly, in the context of the pandemic, the number of recorded bookings for the 2020 Festival is drastically reduced.
17.5 Tidy the text
Given that these data were obtained from an API that outputs data originally in HTML format, some of the text still contains some HTML and PHP encodings for e.g. bold font or paragraphs. We’ll need to get rid of this, as well as other punctuation before analyzing these data.
The below set of commands takes the event descriptions, extracts individual words, and counts the number of times they appear in each of the years covered by our book festival data.
#get year and word for every word and date pair in the dataset
tidy_des <- evdes %>%
mutate(desc = tolower(description)) %>%
unnest_tokens(word, desc) %>%
filter(str_detect(word, "[a-z]"))17.6 Back to the Fringe
We see that the resulting dataset is large (~446k rows). This is because the above commands have first taken the events text, and has “mutated” it into a set of lower case character string. With the “unnest_tokens” function it has then taken each individual string and create a new column called “word” that contains each individual word contained in the event description texts.
Some terminology is also appropriate here. When we tidy our text into this format, we often refer to these data structures as consisting of “documents” and “terms.” This is because by “tokenizing” our text with the “unnest_tokens” functions we are generating a dataset with one term per row.
Here, our “documents” are the collection of descriptions for all events in each year at the Edinburgh Book Festival. The way in which we sort our text into “documents” depends on the choice of the individual researcher.
Instead of by year, we might have wanted to sort our text into “genre.” Here, we have two genres: “Literature” and “Children.” Had we done so, we would then have only two “documents,” which contained all of the words included in the event descriptions for each genre.
Alternatively, we might be interested in the contributions of individual authors over time. Were this the case, we could have sorted our text into documents by author. In this case, each “document” would represent all the words included in event descriptions for events by the given author (many of whom do have multiple appearances over time or in the same festival for a given year).
We can yet tidy this further, though. First we’ll remove all stop words and then we’ll remove all apostrophes:
We see that the number of rows in our dataset reduces by about half to ~223k rows. This is natural since a large proportion of any string will contain many so-called “stop words”. We can see what these stop words are by typing:
stop_words## # A tibble: 1,149 × 2
## word lexicon
## <chr> <chr>
## 1 a SMART
## 2 a's SMART
## 3 able SMART
## 4 about SMART
## 5 above SMART
## 6 according SMART
## 7 accordingly SMART
## 8 across SMART
## 9 actually SMART
## 10 after SMART
## # ℹ 1,139 more rowsThis is a lexicon (list of words) included in the tidytext package produced by Julia Silge and David Robinson (see here). We see it contains over 1000 such words. We remove them here because they are not very informative if we are interested in the substantive content of text (rather than, say, its grammatical content).
Now let’s have a look at the most common words in these data:
## # A tibble: 24,995 × 2
## word n
## <chr> <int>
## 1 rsquo 5638
## 2 book 2088
## 3 event 1356
## 4 author 1332
## 5 world 1240
## 6 story 1159
## 7 join 1095
## 8 em 1064
## 9 life 879
## 10 strong 864
## # ℹ 24,985 more rowsWe can see that one of the most common words is “rsquo,” which is an HTML encoding for an apostrophe. Clearly we need to clean the data a bit more. This is a common issue in large-n text analysis and is a key step if you want to conduct reliably robust forms of text analysis. We’ll have another go using the the filter command, specifying that we only keep the words that are not included in the string of words rsquo, em, ndash, nbsp, lsquo.
remove_reg <- c("&","<",">","<p>", "</p>","&rsquo", "‘", "'", "<strong>", "</strong>", "rsquo", "em", "ndash", "nbsp", "lsquo", "strong")
tidy_des <- tidy_des %>%
filter(!word %in% remove_reg)## # A tibble: 24,989 × 2
## word n
## <chr> <int>
## 1 book 2088
## 2 event 1356
## 3 author 1332
## 4 world 1240
## 5 story 1159
## 6 join 1095
## 7 life 879
## 8 stories 860
## 9 chaired 815
## 10 books 767
## # ℹ 24,979 more rowsThat’s more like it! The words that feature most seem to make sense now (and are actual words rather than random HTML and UTF-8 encodings).
Let’s now collect these words into a data.frame object, which we’ll call edbf_term_counts:
head(edbf_term_counts)## # A tibble: 6 × 3
## # Groups: year [6]
## year word n
## <dbl> <chr> <int>
## 1 2016 book 295
## 2 2018 book 283
## 3 2019 book 265
## 4 2012 book 254
## 5 2013 book 241
## 6 2015 book 239For each year, we see that “book” is the most common word… perhaps no surprises here. But this is some evidence that we’re properly pre-processing and cleaning the data. Cleaning text data is an important element of preparing for any text analysis. It is often a process of trial and error as not all text data looks alike, may come from e.g. webpages with HTML encoding, unrecognized fonts or unicode, and all of these have the potential to cause issues! But finding these errors is also a chance to get to know your data…
17.7 Analyze keywords
Okay, now we have our list of words, and the number of times they appear, we can tag those words we think might be related to issues of gender inequality and sexism. You may decide that this list is imprecise or inexhaustive. If so, then feel free to change the terms we are including after the grepl() function.
edbf_term_counts$womword <- as.integer(grepl("women|feminist|feminism|gender|harassment|sexism|sexist",
x = edbf_term_counts$word))
head(edbf_term_counts)## # A tibble: 6 × 4
## # Groups: year [6]
## year word n womword
## <dbl> <chr> <int> <int>
## 1 2016 book 295 0
## 2 2018 book 283 0
## 3 2019 book 265 0
## 4 2012 book 254 0
## 5 2013 book 241 0
## 6 2015 book 239 017.8 Compute aggregate statistics
Now that we have tagged individual words relating to gender inequality and feminism, we can sum up the number of times these words appear each year and then denominate them by the total number of words in the event descriptions.
The intuition here is that any increase or decrease in the percentage of words relating to these issues is capturing a substantive change in the representation of issues related to sex and gender.
What do we think of this measure? Is this an adequate measure of representation for such issues in the cultural sphere?
Are the keywords we used precise enough? If not, what would you change?
#get counts by year and word
edbf_counts <- edbf_term_counts %>%
group_by(year) %>%
mutate(year_total = sum(n)) %>%
filter(womword==1) %>%
summarise(sum_wom = sum(n),
year_total= min(year_total))
head(edbf_counts)## # A tibble: 6 × 3
## year sum_wom year_total
## <dbl> <int> <int>
## 1 2012 22 23146
## 2 2013 40 23277
## 3 2014 30 25366
## 4 2015 24 22158
## 5 2016 34 24356
## 6 2017 55 2760217.9 Plot time trends
So what do we see? Let’s take the count of words relating to gender in this dataset, and denominate them by the total number of words in these data per year.
ggplot(edbf_counts, aes(year, sum_wom / year_total, group=1)) +
geom_line() +
xlab("Year") +
ylab("% gender-related words") +
scale_y_continuous(labels = scales::percent_format(),
expand = c(0, 0), limits = c(0, NA)) +
theme_tufte(base_family = "Helvetica") 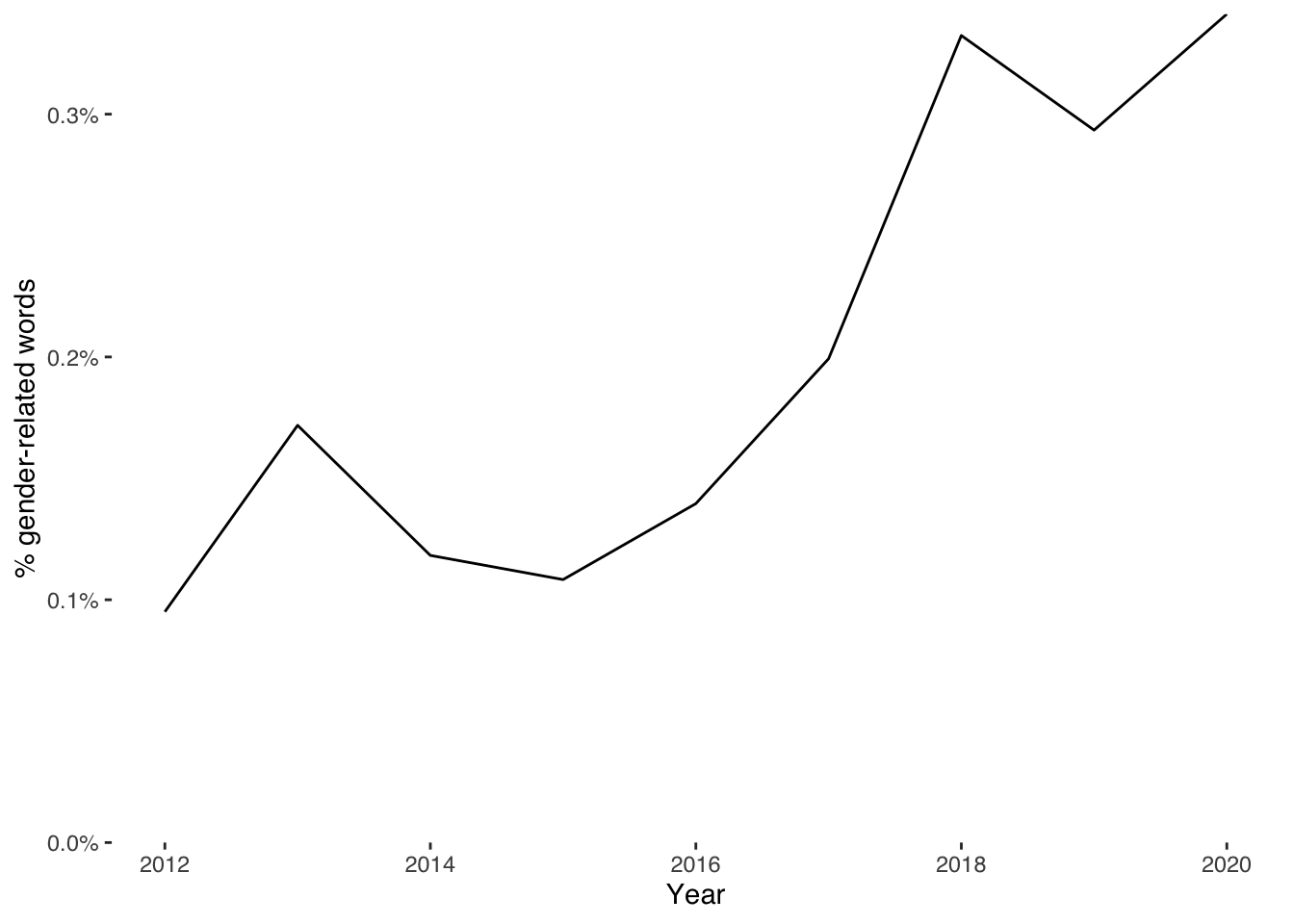
We can add visual guides to draw attention to apparent changes in these data. Here, we might wish to signal the year of the #MeToo movement in 2017.
ggplot(edbf_counts, aes(year, sum_wom / year_total, group=1)) +
geom_line() +
geom_vline(xintercept = 2017, col="red") +
xlab("Year") +
ylab("% gender-related words") +
scale_y_continuous(labels = scales::percent_format(),
expand = c(0, 0), limits = c(0, NA)) +
theme_tufte(base_family = "Helvetica")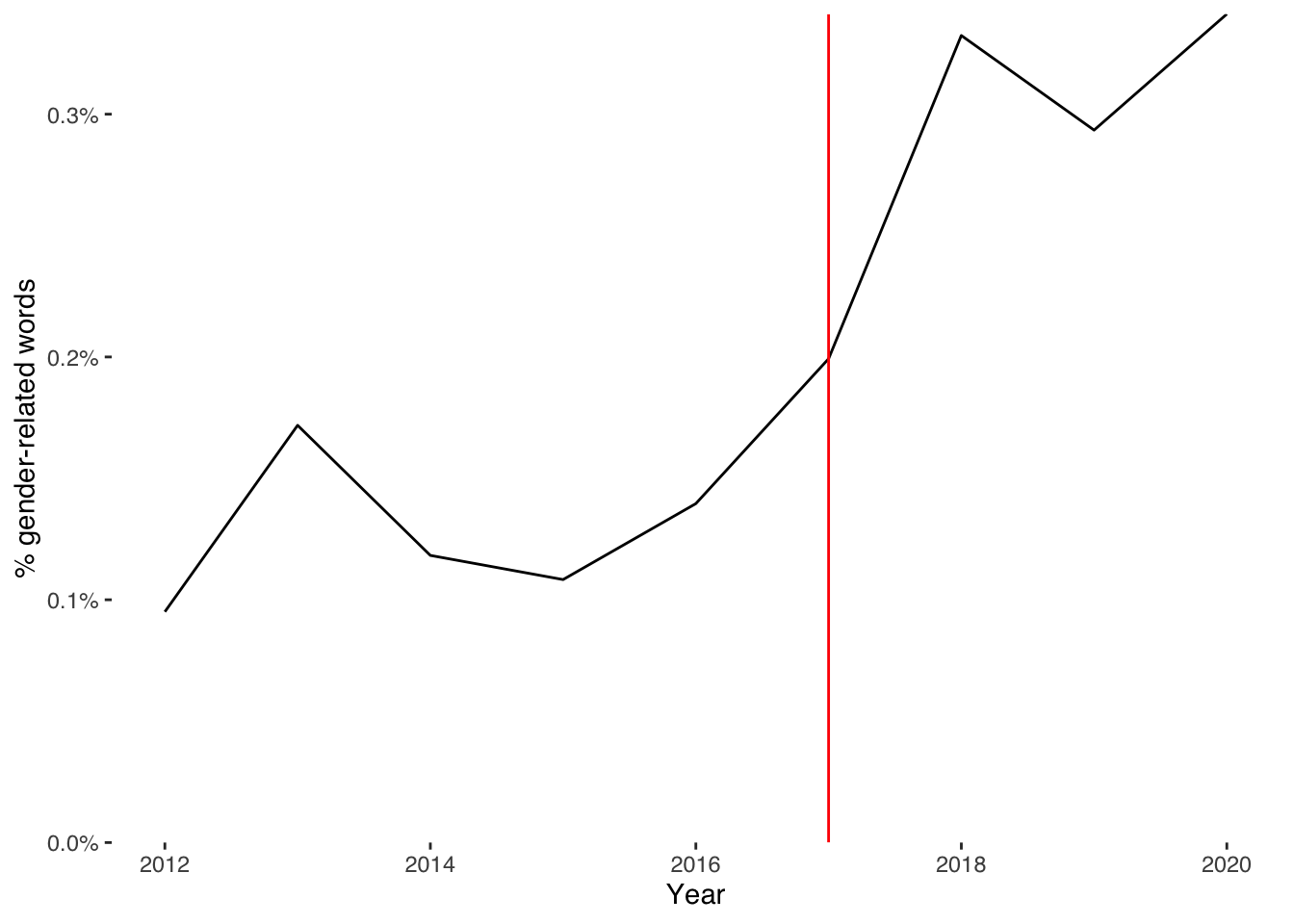
And we could label why we are highlighting the year of 2017 by including a text label along the vertical line.
ggplot(edbf_counts, aes(year, sum_wom / year_total, group=1)) +
geom_line() +
geom_vline(xintercept = 2017, col="red") +
geom_text(aes(x=2017.1, label="#metoo year", y=.0015),
colour="black", angle=90, text=element_text(size=8)) +
xlab("Year") +
ylab("% gender-related words") +
scale_y_continuous(labels = scales::percent_format(),
expand = c(0, 0), limits = c(0, NA)) +
theme_tufte(base_family = "Helvetica")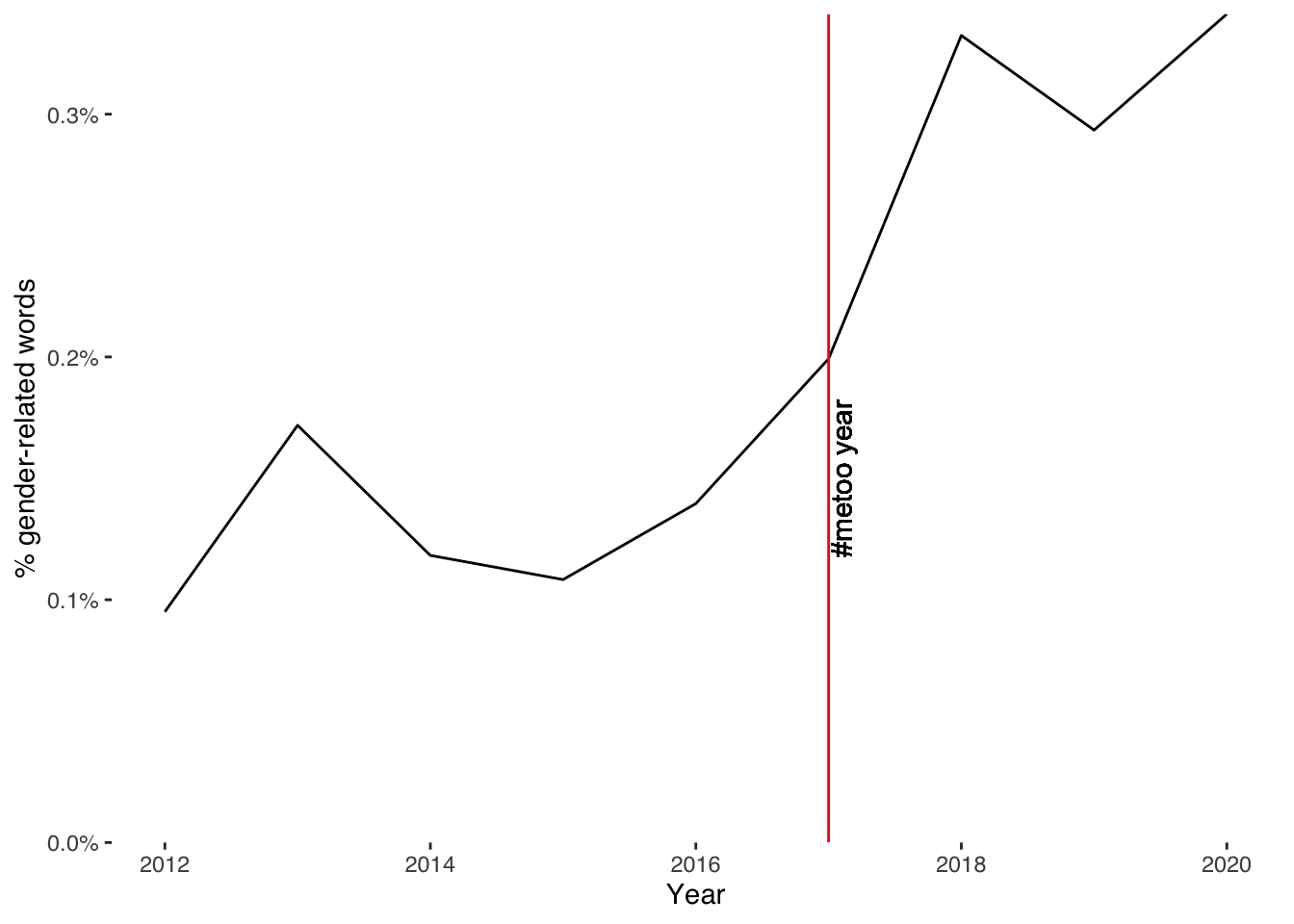
17.10 Bonus: gender prediction
We might decide that this measure is inadequate or too expansive to answer the question at hand. Another way of measuring representation in cultural production is to measure the gender of the authors who spoke at these events.
Of course, this would take quite some time if we were to individually code each of the approximately 6000 events included in this dataset.
But there do exist alternative techniques for imputing gender based on the name of an individual.
We first create a new data.frame object, selecting just the columns for artist name and year. Then we generate a new column containing just the artist’s (author’s) first name:
# get columns for artist name and year, omitting NAs
gendes <- edbfdata %>%
select(artist, year) %>%
na.omit()
# generate new column with just the artist's (author's) first name
gendes$name <- sub(" .*", "", gendes$artist)A set of packages called gender and genderdata used to make the process of predicting gender based on a given individual’s name pretty straightforward. This technique worked with reference to U.S. Social Security Administration baby name data.
Given that the most common gender associated with a given name changes over time, the function also allows us to specify the range of years for the cohort in question whose gender we are inferring. Given that we don’t know how wide the cohort of artists is that we have here, we could specify a broad range of 1920-2000.
genpred <- gender(gendes$name,
years = c(1920, 2000))Unfortunately, this package no longer works with newer versions of R; fortunately, I have recreated it using the original “babynames” data, which comes bundled in the babynames package.
You don’t necessarily have to follow each step of how I have done this—I include this information for the sake of completeness.
The babynames package. contains, for each year, the number of children born with a given name, as well as their sex. With this information, we can then calculate the total number of individuals with a given name born for each sex in a given year.
Given we also have the total number of babies born in total cross these records, we can denominate (divide) the sums for each name by the total number of births for each sex in each year. We can take this proportion as representing the probability that a given individual in our Edinburgh Fringe dataset is male or female.
More information on the babynames package can be found here.
We first load the babynames package into the R environment as a data.frame object. Because the data.frame “babynames” is contained in the babynames package we can just call it as an object and store it with .
This dataset contains names for all years over a period 1800–2019. The variable “n” represents the number of babies born with the given name and sex in that year, and the “prop” represents, according to the package materials accessible here, “n divided by total number of applicants in that year, which means proportions are of people of that gender with that name born in that year.”
babynames <- babynames
head(babynames)## # A tibble: 6 × 5
## year sex name n prop
## <dbl> <chr> <chr> <int> <dbl>
## 1 1880 F Mary 7065 0.0724
## 2 1880 F Anna 2604 0.0267
## 3 1880 F Emma 2003 0.0205
## 4 1880 F Elizabeth 1939 0.0199
## 5 1880 F Minnie 1746 0.0179
## 6 1880 F Margaret 1578 0.0162We then calculate the total number of babies of female and male sex born in each year. Then we merge these to get a combined dataset of male and female baby names by year. We then merge this information back into the original babynames data.frame object.
totals_female <- babynames %>%
filter(sex=="F") %>%
group_by(year) %>%
summarise(total_female = sum(n))
totals_male <- babynames %>%
filter(sex=="M") %>%
group_by(year) %>%
summarise(total_male = sum(n))
totals <- merge(totals_female, totals_male)
totsm <- merge(babynames, totals, by = "year")
head(totsm)## year sex name n prop total_female total_male
## 1 1880 F Mary 7065 0.07238359 90993 110491
## 2 1880 F Anna 2604 0.02667896 90993 110491
## 3 1880 F Emma 2003 0.02052149 90993 110491
## 4 1880 F Elizabeth 1939 0.01986579 90993 110491
## 5 1880 F Minnie 1746 0.01788843 90993 110491
## 6 1880 F Margaret 1578 0.01616720 90993 110491We can then calculate, for all babies born on or after 1920, the number of babies born with that name and sex. With this information, we can then get the proportion of all babies with a given name that were of a particular sex. For example, if 92% of babies born with the name “Mary” were female, this would give us a .92 probability that an individual with the name “Mary” is female.
We do this for every name in the dataset, excluding names for which the proportion is equal to .5; i.e., for names that we cannot adjudicate between whether they are more or less likely male or female.
totprops <- totsm %>%
filter(year >= 1920) %>%
group_by(name, year) %>%
mutate(sumname = sum(n),
prop = ifelse(sumname==n, 1,
n/sumname)) %>%
filter(prop!=.5) %>%
group_by(name) %>%
slice(which.max(prop)) %>%
summarise(prop = max(prop),
totaln = sum(n),
name = max(name),
sex = unique(sex))
head(totprops)## # A tibble: 6 × 4
## name prop totaln sex
## <chr> <dbl> <int> <chr>
## 1 Aaban 1 5 M
## 2 Aabha 1 7 F
## 3 Aabid 1 5 M
## 4 Aabir 1 5 M
## 5 Aabriella 1 5 F
## 6 Aada 1 5 FOnce we have our proportions for all names, we can then merge these back with the names of our artists from the Edinburgh Fringe Book Festival. We can then easily plot the proportion of artists at the Festival who are male versus female in each year of the Festival.
ednameprops <- merge(totprops, gendes, by = "name")
ggplot(ednameprops, aes(x=year, fill = factor(sex))) +
geom_bar(position = "fill") +
xlab("Year") +
ylab("% women authors") +
labs(fill="") +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
theme_tufte(base_family = "Helvetica") +
geom_abline(slope=0, intercept=0.5, col = "black",lty=2)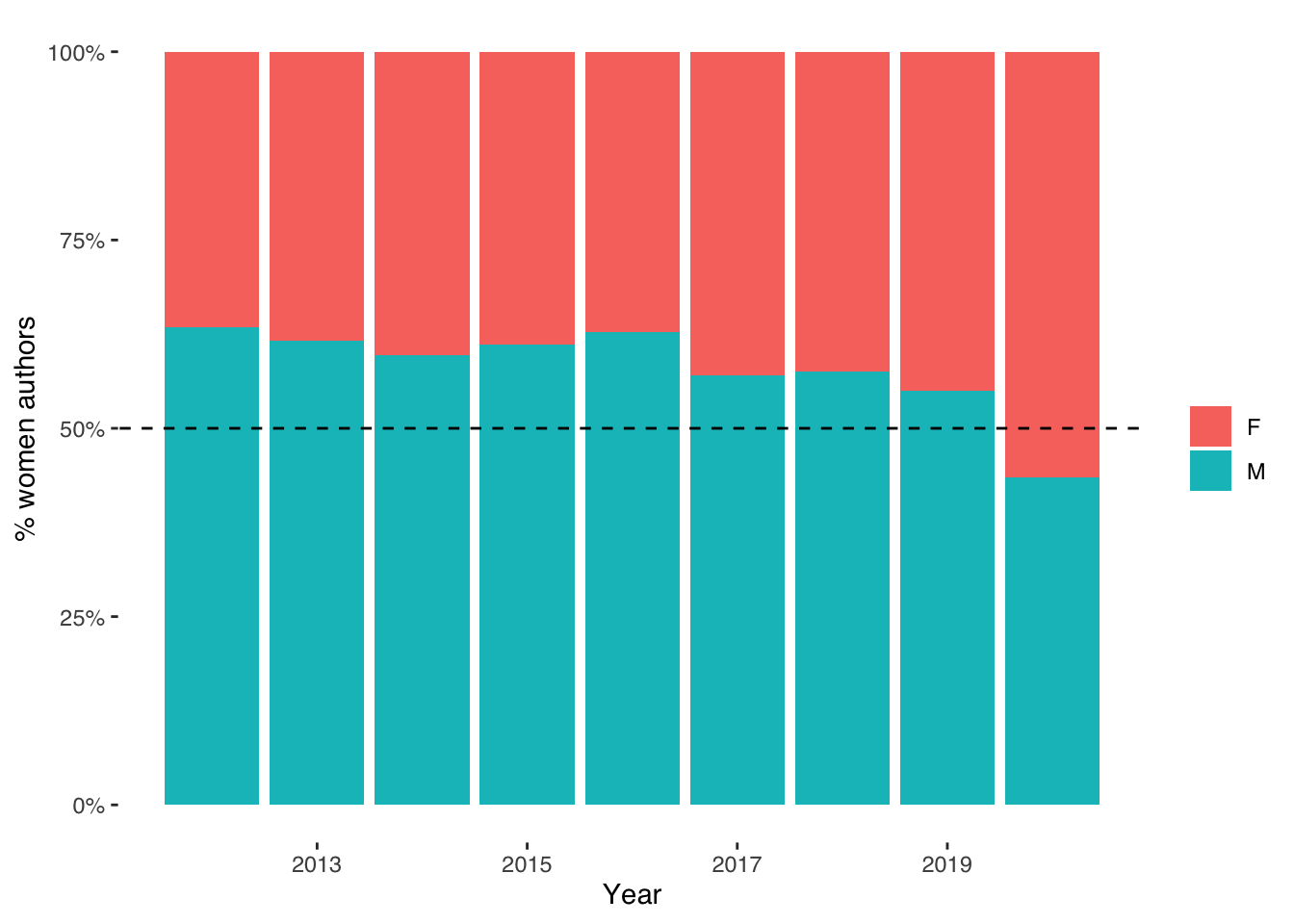
What can we conclude form this graph?
Note that when we merged the proportions from th “babynames” data with our Edinburgh Fringe data we lost some observations. This is because some names in the Edinburgh Fringe data had no match in the “babynames” data. Let’s look at the names that had no match:
names1 <- ednameprops$name
names2 <- gendes$name
diffs <- setdiff(names2, names1)
diffs## [1] "L" "Kapka" "Menzies"
## [4] "Ros" "G" "Pankaj"
## [7] "Uzodinma" "Rodge" "A"
## [10] "Zoë" "László" "Sadakat"
## [13] "Michèle" "Maajid" "Yrsa"
## [16] "Ahdaf" "Noo" "Dilip"
## [19] "Sjón" "François" "J"
## [22] "K" "Aonghas" "S"
## [25] "Bashabi" "Kjartan" "Romesh"
## [28] "T" "Chibundu" "Yiyun"
## [31] "Fiammetta" "W" "Sindiwe"
## [34] "Cat" "Jez" "Fi"
## [37] "Sunder" "Saci" "C.J"
## [40] "Halik" "Niccolò" "Sifiso"
## [43] "C.S." "DBC" "Phyllida"
## [46] "R" "Struan" "C.J."
## [49] "SF" "Nadifa" "Jérome"
## [52] "D" "Xiaolu" "Ramita"
## [55] "John-Paul" "Ha-Joon" "Niq"
## [58] "Andrés" "Sasenarine" "Frane"
## [61] "Alev" "Gruff" "Line"
## [64] "Zakes" "Pip" "Witi"
## [67] "Halsted" "Ziauddin" "J."
## [70] "Åsne" "Alecos" "."
## [73] "Julián" "Sunjeev" "A.C.S"
## [76] "Etgar" "Hyeonseo" "Jaume"
## [79] "A." "Jesús" "Jón"
## [82] "Helle" "M" "Jussi"
## [85] "Aarathi" "Shappi" "Macastory"
## [88] "Odafe" "Chimwemwe" "Hrefna"
## [91] "Bidisha" "Packie" "Tahmima"
## [94] "Sara-Jane" "Tahar" "Lemn"
## [97] "Neu!" "Jürgen" "Barroux"
## [100] "Jan-Philipp" "Non" "Metaphrog"
## [103] "Wilko" "Álvaro" "Stef"
## [106] "Erlend" "Grinagog" "Norma-Ann"
## [109] "Fuchsia" "Giddy" "Joudie"
## [112] "Sav" "Liu" "Jayne-Anne"
## [115] "Wioletta" "Sinéad" "Katherena"
## [118] "Siân" "Dervla" "Teju"
## [121] "Iosi" "Daša" "Cosey"
## [124] "Bettany" "Thordis" "Uršuľa"
## [127] "Limmy" "Meik" "Zindzi"
## [130] "Dougie" "Ngugi" "Inua"
## [133] "Ottessa" "Bjørn" "Novuyo"
## [136] "Rhidian" "Sibéal" "Hsiao-Hung"
## [139] "Audur" "Sadek" "Özlem"
## [142] "Zaffar" "Jean-Pierre" "Lalage"
## [145] "Yaba" "H" "DJ"
## [148] "Sigitas" "Clémentine" "Celeste-Marie"
## [151] "Marawa" "Ghillie" "Ahdam"
## [154] "Suketu" "Goenawan" "Niviaq"
## [157] "Steinunn" "Shoo" "Ibram"
## [160] "Venki" "DeRay" "Diarmaid"
## [163] "Serhii" "Harkaitz" "Adélaïde"
## [166] "Agustín" "Jérôme" "Siobhán"
## [169] "Nesrine" "Jokha" "Gulnar"
## [172] "Uxue" "Taqralik" "Tayi"
## [175] "E" "Dapo" "Dunja"
## [178] "Maaza" "Wayétu" "Shokoofeh"Do we notice anything about these names? What does this tell us about the potential biases of using such sources as US baby names data as a foundation for gender prediction? What are alternative ways we might go about this task?